
This is my final report of TensorFlow class at UCSC.
Abstract
In this report, we describe that how to prepare dataset and improve the performance of the CNN based lane segmentation by using transfer learning. In addition, we evaluate and compare four types of the methods for lanes segmentation such as the simple rule based method, the CNN based method trained with daytime dataset, the CNN trained daytime dataset filtered gamma correction, and the CNN trained high diversity road dataset.


1. Introduction
In recent years, some automotive companies provide cars which have ADAS(advanced driver assistance system) function for reducing car accidents. This kind of systems provide drivers more comfortable and safety experience. To develop perception phase of the ADAS, lane segmentation is one of the most difficult and important function. Because if it fault detects another area as lanes area, the later function such as curve fitting algorithm will confuse and it can be a dangerous system.
A most simple way to build lane detection system is using rule based algorithm which are RGB or HSV threshold filter and edge detection algorithm such as canny edge. We can find thousands of repositories inspired by the advanced lane detection of Udacity Car Nanodegree[1] in the github. These simple methods are enough to use for inside application such as manufactory robot but not real road situation. Because if we determine threshold parameters such as color, luminate and edge for specific road images, the system could fault detection the objects which have same color or luminate as lane area when it is in the another situation.
To develop robust lane detection system, we are able to use CNN based approach instead of rule based method. In this paper, we describe how to select suitable CNN model for our application by the requirement of our use case. In addition, we explain preparing ground truth images from dataset and result of transfer learning. Finally, we evaluate three types of CNN settings which are trained different dataset, and compare them and rule based methods. An overview of the result can be seen in Fig. 1.


2. Methods
2.1. Appropriate choice of architecture
Tusimple Lane Detection Challenge 2017[2] is one of the helpful competitions to build suitable CNN model for lane detection. The reason why, we are able to read the papers and implementation codes of SCNN[3] and LaneNet[4] in the arxiv and github. SCNN means spatial CNN for traffic scene understanding and got 1st place at the TuSimple competition. On the other hand, LaneNet got 3rd place, and it is builded based on ENet[5] using an instance segmentation approach to detect lane. The CNN architecture of SCNN and LaneNet can be seen in Table I. SCNN architecture is deeper than
LaneNet.
| Type | Name | Size/Stride | Outt | Type | Name | Size/Stride | Out | |
|---|---|---|---|---|---|---|---|---|
| Conv+BN+ReLU | conv1_1 | 3×3 | 64 | Conv+BN+ReLU | conv1_1 | 3×3 | 64 | |
| Conv+BN+ReLU | conv1_2 | 3×3 | 64 | Conv+BN+ReLU | conv1_2 | 3×3 | 64 | |
| Maxpool | pool1 | 2×2/2 | 128 | Maxpool | pool1 | 2×2/2 | 128 | |
| Conv+BN+ReLU | conv2_1 | 3×3 | 128 | Conv+BN+ReLU | conv2_1 | 3×3 | 128 | |
| Conv+BN+ReLU | conv2_2 | 3×3 | 128 | Conv+BN+ReLU | conv2_2 | 3×3 | 128 | |
| Maxpool | pool2 | 2×2/2 | 256 | Maxpool | pool2 | 2×2/2 | 256 | |
| Conv+BN+ReLU | conv3_1 | 3×3 | 256 | Conv+BN+ReLU | conv3_1 | 3×3 | 256 | |
| Conv+BN+ReLU | conv3_2 | 3×3 | 256 | Conv+BN+ReLU | conv3_2 | 3×3 | 256 | |
| Conv+BN+ReLU | conv3_3 | 3×3 | 256 | Conv+BN+ReLU | conv3_3 | 3×3 | 256 | |
| Maxpool | pool3 | 2×2/2 | 512 | Maxpool | pool3 | 2×2/2 | 512 | |
| Conv+BN+ReLU | conv4_1 | 3×3 | 512 | Conv+BN+ReLU | conv4_1 | 3×3 | 512 | |
| Conv+BN+ReLU | conv4_2 | 3×3 | 512 | Conv+BN+ReLU | conv4_2 | 3×3 | 512 | |
| Conv+BN+ReLU | conv4_3 | 3×3 | 512 | Conv+BN+ReLU | conv4_3 | 3×3 | 512 | |
| Maxpool | pool4 | 2×2/2 | 512 | Maxpool | pool4 | 2×2/2 | 512 | |
| AtrousConv+BN+ReLU | conv5_1 | 3×3 | 512 | Conv+BN+ReLU | conv5_1 | 3×3 | 512 | |
| AtrousConv+BN+ReLU | conv5_2 | 3×3 | 512 | Conv+BN+ReLU | conv5_2 | 3×3 | 512 | |
| AtrousConv+BN+ReLU | conv5_3 | 3×3 | 512 | Conv+BN+ReLU | conv5_3 | 3×3 | 512 | |
| AtrousConv+BN+ReLU | conv5_4 | 3×3 | 1024 | Maxpool | pool5 | 2×2/2 | 512 | |
| Conv+BN+ReLU | conv5_5 | 1×1 | 128 | |||||
| Conv+ReLU | conv6_1 | 1×9 | 128 | |||||
| Conv+ReLU | conv6_2 | 1×9 | 128 | |||||
| Conv+ReLU | conv6_3 | 9×1 | 128 | |||||
| Conv+ReLU | conv6_4 | 9×1 | 128 | |||||
| Conv | conv_6 | 1×1 | 5 |
| (a) SCNN | (b) LaneNet |
Table II shows performance of the two methods. According to the paper of LaneNet, SCNN is more precise than LaneNet about 0.1% for accuracy of TuSimple dataset. In addition, we measured the processing speed for a image on a general gaming pc. However, LaneNet is faster than SCNN about 5.83 times. To develop real time application such as ADAS system, we should care about processing speed to control vehicle accurately, and perception phase must be over 20 fps and within 50 milliseconds. For those reason, we choose LaneNet model as our base model.
| SCNN | LaneNet | |
|---|---|---|
| Accuracy of TuSimple dataset (Trained 3626 and tested 2782 images) |
96.53 % | 96.4 % |
| Processing speed (i9-9900k, 16GB, SSD, RTX2800) |
70 msec (800×288) |
12 msec (512×256) |
TABLE II Performance of SCNN and LaneNet
2.2. Data preparation
The TuSimple dataset has 3626 images for training and 2782 images for validation. However, it contains only daytime images. To build robust lane segmentation, we should prepare dataset includes nighttime images. There are two types of new dataset we can make.
First, add some image processing filter to TuSimple Dataset, and use as nighttime dataset. We use gamma correction algorithm to implement this method, and 0.4 as the variable of gamma filter.
Second, using new dataset such as BDD100K. It contains 70,000 for training, 20,000 for testing and 10,000 for validation images. We need only highway dataset for our application. Therefore, we selected 10,460 highway images from the dataset for training using the label which have annotations of road objects, lanes, and drivable areas in JSON format. These selected images contain highway category and over four horizontal lane edges, but do not have any vertical lanes and traffic lights.
We should remind that the binary lane images as using ground truth made by labeling data are different between TuSimple and BDD100K dataset. TuSimple dataset uses single line for one lane, on the other hand, BDD100K dataset labels two lines for one lane that can be seen in Fig.2.


2.3. Data visualization
Fig.3 shows three types of datasets we prepared 2.2. Data preparation. We picked 12 images randomly from the each training datasets. The images of TuSimple dataset were taken by one specific car, but the images BDD100K dataset were taken many kinds of cars.



| (a) TuSimple | (b) Dark TuSimple | (c) BDD100K selected highway scenes |
2.4. Visualizing the learning process
We have already have pre-trained weights for TuSimple dataset. Thus only two datasets are needed to be trained, which are the dark TuSimple and BDD100k selected highway scenes. Fig.4 shows the process of the transfer learning using the pre-trained weights. We trained 5000 steps for dark TuSimple dataset, and 10000 steps for BDD100K with 10 noof batches. In the dark TuSimple dataset, it shows high accuracy which is 0.95 within 5000 steps. The reason why, it is quite similar to the dataset used the pre-trained weights. On the other hand, the process of BDD100K only leached to 0.45 accuracy even we trained 10000 steps with 10 noof batches. Because it is different dataset from the pre-trained weights, in addition the images of dataset taken by many types of cars. We stopped learning process because it took about 19 hours using our personal computer (i9-9900k, 16GB, SSD, RTX2800), but if we have time to train more, the accuracy of the model could be better than this result.
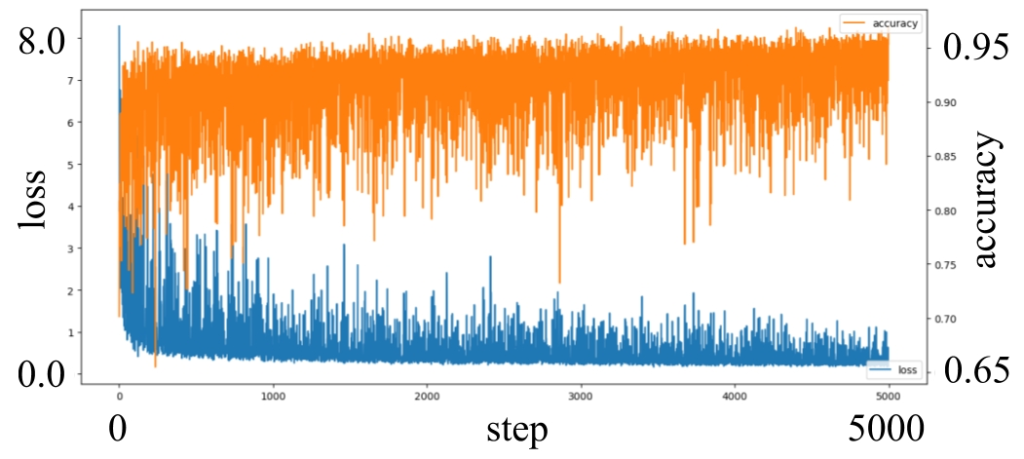
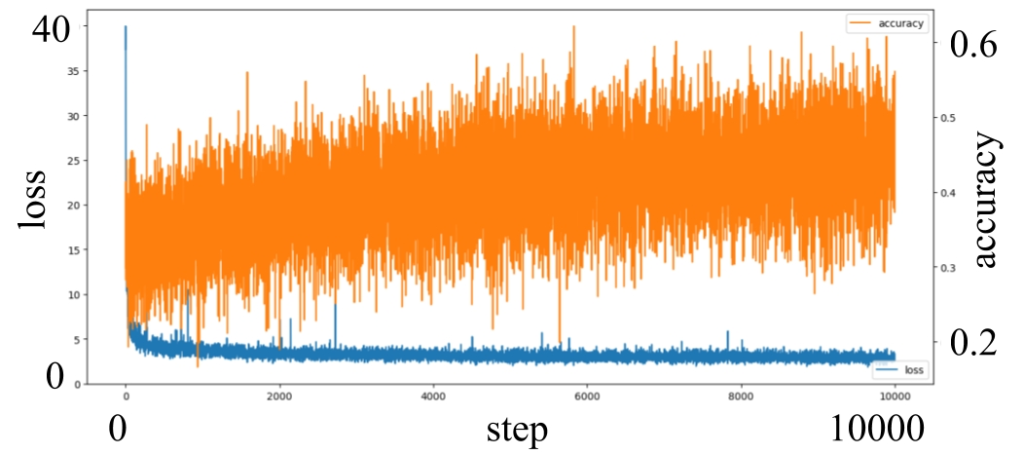
| (a) Dark TuSimple | (b) BDD100K selected highway scenes |
3. Results
3.1. Description of the Python program
The all python scripts can be seen in the github repository[a]. The codes were written by python 3.6, and shows the process easily intuitively by using Jupyter Notebook. This repository is able to be divided four parts. And final script of the each part generate two mp4 files contain daytime and nighttime to show lane segmentation.
First, we experiment simple rule based lane detection[a-1] inspired by Udacity Car Nanodegree[1]. The code has a multi_threshold function that can generate binary image using LAB, HLS and HSV thresholds. In addition, apply_canny function can generate canny edge detection. Before processing videos, the code combines above outputs of algorithm, and masks top and bottom area that do not be needed to do lane segmentation.
Second, we experiment LaneNet lane segmentation[a-2] which are pre-trained by TuSimple dataset inspired by LaneNet[4]. The script does not have any threshold function such as color and brightness. To implement LaneNet we use VGG16 encoder[7].
Third, we experiment tuned LaneNet lane segmentation by transfer learned using dark TuSimple dataset[a-3-x]. We can understand TuSimple dataset by using random picking script[a-3-1]. To generate dark TuSimple dataset, gamma correction algorithm with 0.4 variable is used[a-3-2]. After preparing dark TuSimple dataset, we transfer learn a LaneNet using pre-trained weights[a-3-3]. The testing script[a-3-4] is same as the second method.
Finally, we experiment other tuned LaneNet lane segmentation by transfer learned using BDD100K dataset[a-4-x]. The script to understand dataset[a-4-1] is almost same as the third method. Also we use drawing script[a-4-2] to understand a labeled JSON file from provided from BDD100K dataset. This BDD100K has images of many kinds of situations. To prepare suitable dataset for our highway application, and to reduce to suitable amount of images, we use picking script[a-4-3] based on the labeled JSON to make new labeled JSON file. The specific conditions are discussed at the 2.2. Data preparation. After selected highway scenes images, we check it simplify by using the show label script[a-4-4]. In addition, the training dataset made by BDD100K should be same format as TuSimple dataset. We use the script[a-4-5] to prepare ground truth binary images such as Fig.2. Also we use the script[a-4-6] to convert png format from jpg., and preparing a list file of images using other script[a-4-7]. After done whole process of preparing new dataset, we can train using the script[a-4-8] for transfer learning, and also test using the script[a-4-9]. These two scripts structure are same as third method.
3.2. Screenshots of the program output
Using validation dataset is most general way to evaluate lane segmentation processing. However, if the system does not have same camera or same position of camera angle, validation dataset is not able to been trusted precisely. On the other hand, building original dataset for our camera is not realistic way for a small laboratory or company like us. In this paper, we check output movie by human eyes and discuss about pro and con. The example of all of the final result can be seen in Fig.5, and the full time videos can be seen in the github[a].
For daytime situation, the all method can detect lane areas. The result of th LaneNet transfer leaned using dark TuSimple is scarce lane segmentation. Because the model optimized for nighttime by training with dark TuSimple dataset. Also the reason of that the lane widths of the forth method result are only thick is differences of labeling way we discussed 2.2.
For nighttime situation, the all methods show different result. The rule based method fault detects other area as lanes. The result of the model trained with dark TuSimple dataset is better than the model trained with normal TuSimple dataset, but it has points noise in the bush. Finally, the LaneNet trained with BDD100K selected highway scenes is most strong and clear result. As Fig.4 shows, the trained accuracy of the fourth method is not higher than the third method. However, from this experiment, the fourth methods can be most robust lane segmentation.
| (a) Daytime result | (b) Nighttime result |
4. Conclusion
In this report, we described that how to prepare dataset and improve the performance of the CNN based lane segmentation by using transfer learning. In addition, we evaluated and compared four types of the methods for lanse segmentation such as the simple rule based method, the CNN based method trained with daytime dataset, the CNN trained artificially nighttime dataset, and the CNN trained high divercity road dataset. We conclude that using high diversity dataset is powerful way to build robust segmentation even it does show weak accuracy in training phase.
References
[1] Udacity Car Nanodegree https://www.udacity.com/school-of-autonomous-systems
[2] TuSimple Challenge 2017 https://github.com/TuSimple/tusimple-benchmark/wiki
[3] X Pan, J Shi, P Luo, X Wang, X Tang. Spatial as deep: Spatial cnn for traffic scene understanding. Thirty-Second AAAI Conference on Artificial Intelligence
[4] D Neven, B De Brabandere, S Georgoulis, M Proesmans, L Van Gool. Towards end-to-end lane detection: an instance segmentation approach. 2018 IEEE Intelligent Vehicles Symposium (IV), 286-291
[5] A. Paszke, A. Chaurasia, S. Kim, E. Culurciello, ENet: A deep neural network architecture for real-time semantic segmentation. CoRRabs/1606.02147, 2016.
[6] BDD100K https://github.com/ucbdrive/bdd-data
[7] VGG16 encoder https://github.com/machrisaa/tensorflow-vgg
Appendix
Requirements for the Python scripts
We experimented using Ubuntu 16.04, Python 3.6.6, OpenCV 3.4.5, Tensorflow 1.13.0-rc2, CUDA 10.0, TensorRT 5.0.2.6 and cuDNN 7.4.2.
Python scripts
[a] https://github.com/shirokunet/lane_segmentation/tree/4ac7b75c27d35415f01b295abf495dc02fea9480
[a-1] 01_Rule-based_lane-detection.ipynb
[a-2] 02_LaneNet_lane-detection.ipynb
[a-3-1] 03-01_Dataset_random_picking.ipynb
[a-3-2] 03-02_Filter_dataset_batch.ipynb
[a-3-3] 03-03_Transfer-learning_LaneNet.ipynb
[a-3-4] 03-04_Tuned_LaneNet_lane-detection.ipynb
[a-4-1] 04-01_Dataset_random_picking.ipynb
[a-4-2] 04-02_dataset_drawbox.ipynb
[a-4-3] 04-03_generate_highway_dataset_json.ipynb
[a-4-4] 04-04_show_labels.ipynb
[a-4-5] 04-05_generate_binary_image_for_bdd100k.ipynb
[a-4-6] 04-06_convert_jpg_to_png.ipynb
[a-4-7] 04-07_generate_train_txt_for_bdd100k.ipynb
[a-4-8] 04-08_Transfer-learning_LaneNet.ipynb
[a-4-9] 04-09_Tuned_LaneNet_lane-detection.ipynb
Leave a Reply